Model: Given a natural-language goal and a video stream of observations, SOLE-R1 produces (i) per-timestep chain-of-thought (CoT) describing what has changed since the last timestep and (ii) a dense scalar progress estimate used as a reward signal for online RL (Figure 1).

Training data: We build the training data (Figure 2) in two stages: (1) foundational reasoning over space (single-image + depth) and time (multi-image/video), and (2) robot-video spatiotemporal reasoning specialized for dense progress estimation. We first carefully curate a diverse collection of general spatial and multi-frame temporal reasoning data (e.g., from SSR-CoT, SpatialVLM, Spot-the-diff, Embodied CoT, RoboVQA, Robo2VLM-Reasoning) to serve as a foundational layer of our training mixture. We then generate over 1 million CoT reasoning examples from more than 40,000 real-world and simulated videos. Together, this training induces video-native reasoning that explicitly integrates both spatial and temporal structure.
Training procedure: To train SOLE-R1, we use a two-stage hybrid recipe: SFT teaches high-quality spatiotemporal CoT reasoning, while RLVR (GRPO) directly emphasizes accurate progress prediction, which is under-emphasized during SFT (since the final answer occupies only a small fraction of response tokens).

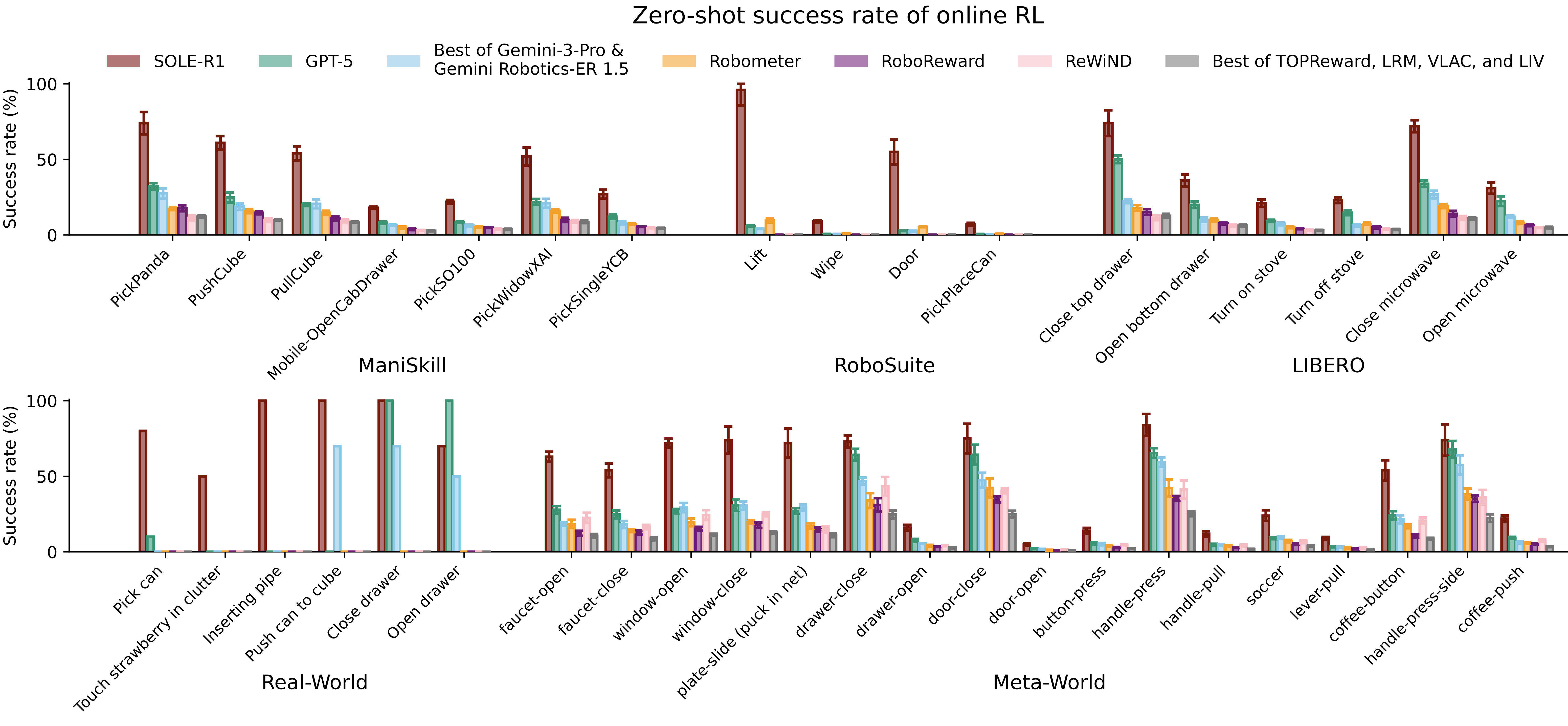
We evaluate whether SOLE-R1 can serve as the sole supervision signal for learning manipulation skills from scratch via online RL.
We run experiments across four simulation benchmark suites (RoboSuite, ManiSkill, Meta-World, and LIBERO) and in a real-world tabletop manipulation setting with a Franka arm.
Across all settings, we evaluate a total of 40 tasks, spanning pick-and-place, articulation, button/lever/knob interactions, and mobile manipulation.
The policy observes two RGB streams (a wrist camera and an external/shoulder camera) along with robot proprioception.
Actions are end-effector delta motions and a gripper open/close command.
We do not use any additional privileged state, depth, object poses, or task-specific sensors.
Unlike prior work that (i) learns from ground-truth rewards and/or (ii) tunes reward models or policies on task demonstrations, we evaluate in a fully zero-shot online RL setting:

SOLE-R1 achieves at least 50% success on 24 tasks, substantially outperforming all baselines (Figure 3). The strongest baselines include GPT-5 and Gemini, but they reach 50% success on only 7 and 5 tasks, respectively.
The non-reasoning
models achieve near-zero success on all tasks, with the exception of Meta-World tasks, where
Robometer, RoboReward, and ReWiND achieve above 40% success rate on 4 tasks.
SOLE-R1 generalizes to unseen tasks and environments.
SOLE-R1 succeeds with tasks that significantly differ from the task types seen during training, such as sliding a puck into a net, opening and closing windows, and manipulating unseen levers and handles in novel ways based on the natural language task specification.
This suggests that SOLE-R1 does not merely memorize task templates, but instead learns reusable spatiotemporal progress primitives (e.g., establishing contact, aligning a grasp, changing articulation state, placing/settling objects) that transfer to unseen tasks.
SOLE-R1 generalizes to unseen embodiments and camera viewpoints.
SOLE-R1 solves tasks with the Franka, along with embodiments not seen during training, including the Sawyer robot in Meta-World, the WidowX AI and Fetch Mobile Manipulator in ManiSkill, and the modified Franka with different gripper fingers and wrist camera angle in real-world.
We also see SOLE-R1 solve tasks with camera views that were not used during training. This indicates that SOLE-R1 reward predictions are not narrowly tied to a particular kinematic chain or gripper appearance, but instead track goal-relevant object state changes across morphology and camera placement.
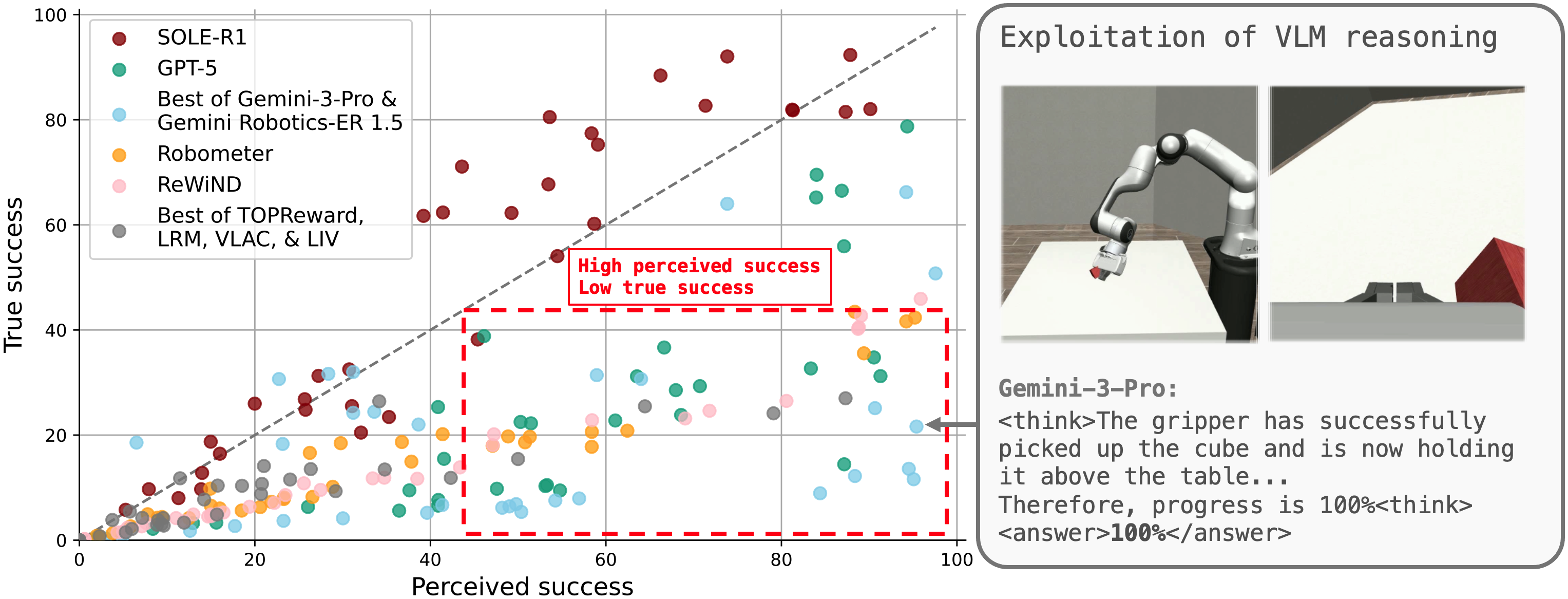
We use the perceived-vs-true success plot (Figure 4) to separate failures into two types: reward-hacking (high perceived, low true) versus signal-limited (low perceived, low true). General-purpose VLM reasoning models (GPT-5 and Gemini) predominantly fail via reward hacking: online RL discovers behaviors that elicit inflated progress predictions without completing the task. We show an example of reward hacking with picking up the cube in Figure 4 (and an extended set of examples in Figure 7 in the paper). SOLE-R1 failures more often fall into the signal-limited failure type, suggesting the model typically recognizes non-success but can still provide rewards that are too flat/noisy to bootstrap exploration within the episode budget.
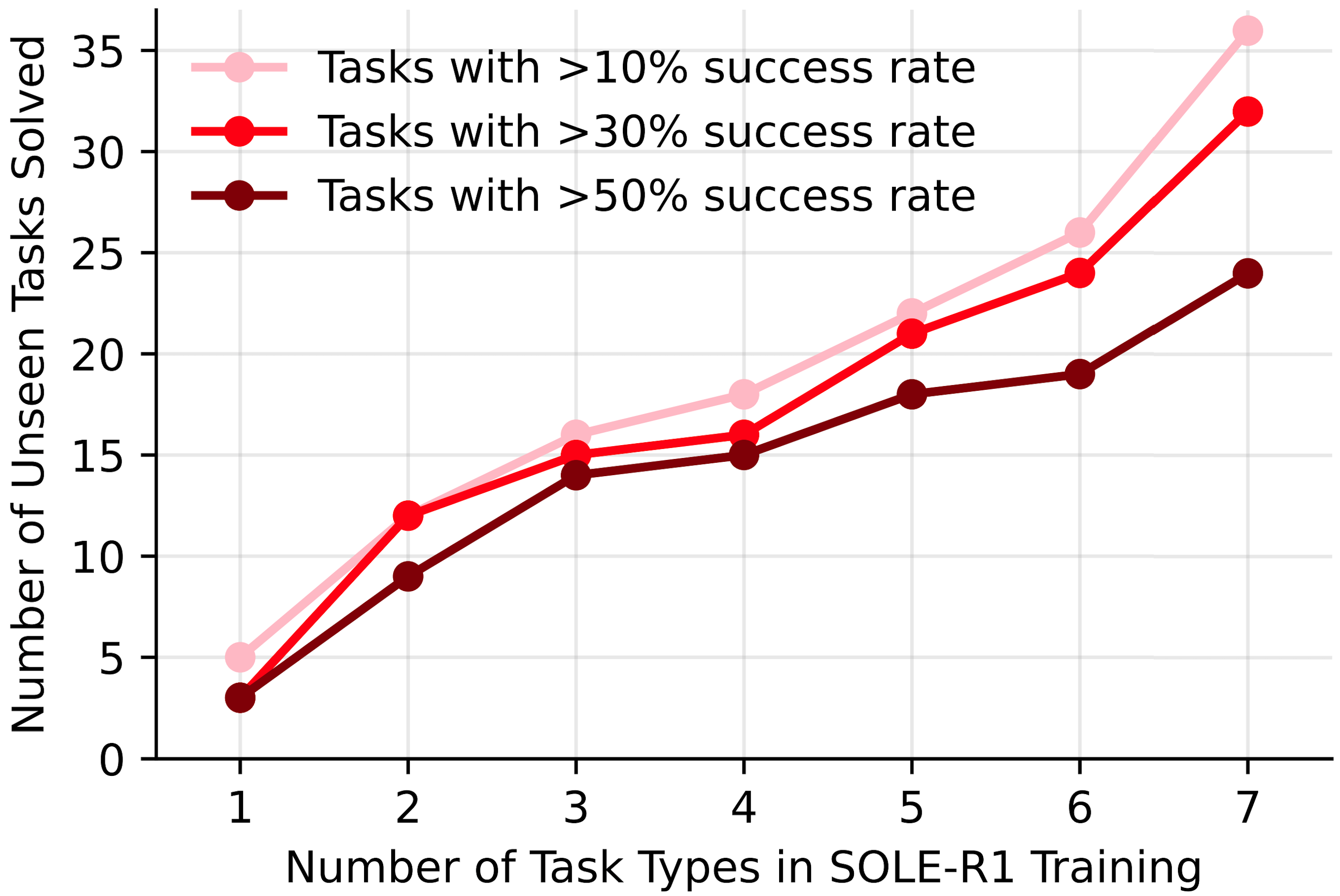
We find that our data synthesis and training recipe follows a scaling law driven by the diversity of training tasks (Figure 6). We train variants of SOLE-R1 with an increasing number of task types included in our training data synthesis (details in Appendix M of the paper). The figure below plots the number of downstream tasks that achieve different success thresholds as a function of training task diversity.
@article{schroeder2026soler1,
title = {SOLE-R1: Video-Language Reasoning as the Sole Reward for On-Robot Reinforcement Learning},
author = {Schroeder, Philip and Weng, Thomas and Schmeckpeper, Karl and Rosen, Eric and Hart, Stephen and Biza, Ondrej},
journal = {arXiv preprint arXiv:2603.28730},
year = {2026},
eprint = {2603.28730},
archivePrefix = {arXiv},
primaryClass = {cs.RO},
doi = {10.48550/arXiv.2603.28730},
url = {https://arxiv.org/abs/2603.28730}
}
